
Opencart SEO Web Брендинг Интернет-магазины Корпоративные сайты и блоги Маркетинг Оптимизация и ускорение
Создаем слайдер с изображением и текстом на React.js с нуля и оптимизируем / Хабр | Веб-студия Nat.od.ua
Создаем слайдер с изображением и текстом на React.js с нуля и оптимизируем / Хабр
В этой статье я хочу затронуть задачу, с которой вы можете столкнуться на собеседовании на позицию Front-End — создание Image Slider.
За последние 5 месяцев у меня было 15 онсайт...

Opencart SEO Web Брендинг Интернет-магазины Корпоративные сайты и блоги Маркетинг Оптимизация и ускорение
Создание WebCron плагина для Joomla 4 (Task Scheduler Plugin) / Хабр | Веб-студия Nat.od.ua
Создание WebCron плагина для Joomla 4 (Task Scheduler Plugin) / Хабр
Эта статья — дополненный перевод статьи How to Create Joomla Task Scheduler Plugin.
В Joomla! появился планировщик задач начиная с версии 4.1. Он помогает автоматизировать повторяющиеся и рутинные...

Opencart SEO Web Брендинг Интернет-магазины Корпоративные сайты и блоги Маркетинг Оптимизация и ускорение
Фронтенд-новости №12. Вышел EcmaScript 2022, фавиконки в 2022, как будет выглядеть веб только с Chromium | Веб-студия Nat.od.ua
Фронтенд-новости №12. Вышел EcmaScript 2022, фавиконки в 2022, как будет выглядеть веб только с Chromium
Дайджест новостей и полезных статей из мира фронтенд-разработки за неделю 20–26 июня.
?♂️Доступность
? Выбор даты и времени для всех. Ребята из Adobe сделали библиотеку...

Opencart SEO Web Брендинг Интернет-магазины Корпоративные сайты и блоги Маркетинг Оптимизация и ускорение
Обзор паттернов хранения деревьев в реляционных БД / Хабр | Веб-студия Nat.od.ua
Обзор паттернов хранения деревьев в реляционных БД / Хабр
Всем привет! Меня зовут Пантелеев Александр и я бэкенд-разработчик в компании Bimeister.
Постараюсь описать исчерпывающе, кратко и понятно суть основных паттернов хранения деревьев в реляционных базах данных....

Opencart SEO Web Брендинг Интернет-магазины Корпоративные сайты и блоги Маркетинг Оптимизация и ускорение
Левитация — а не отделить ли нам сайт от движка? / Хабр | Веб-студия Nat.od.ua
Левитация — а не отделить ли нам сайт от движка? / Хабр
200 лет назад начались разборки с авто двигателем. Понадобилось 80 лет для создания двигателя внутреннего сгорания. Результатом разборок стало появление сразу двух индустрий — автомобилестроение и моторостроение.
20...
Opencart SEO Web Брендинг Интернет-магазины Корпоративные сайты и блоги Маркетинг Оптимизация и ускорение
UI редактора блок-схем / Хабр | Веб-студия Nat.od.ua
UI редактора блок-схем / Хабр
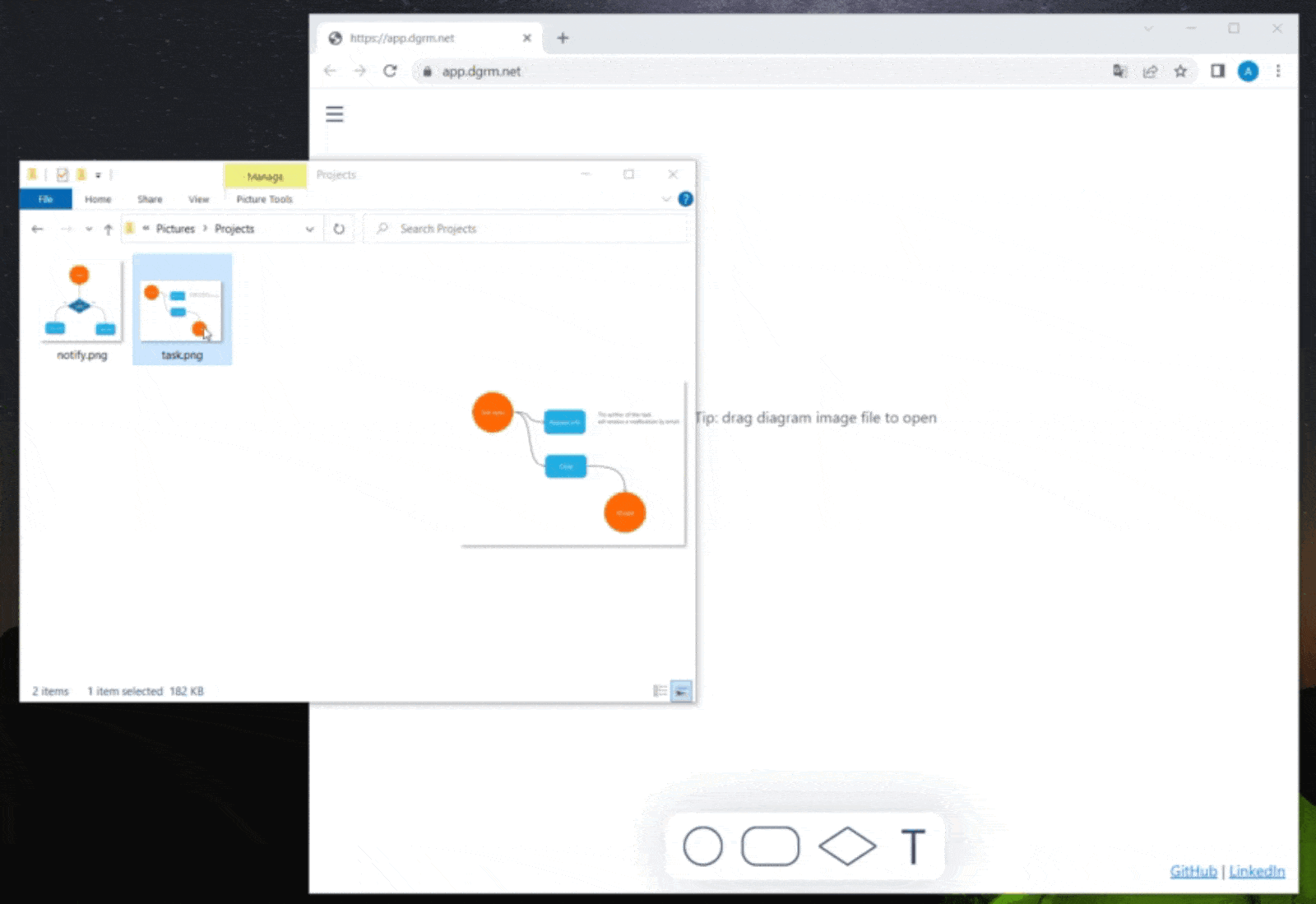
Dgrm.net
Придумывать интерфейс интересно. Похоже на головоломку. Вот что получается для Dgrm.net.
Dgrm.net это редактор блок-схем
работает на пк, планшетах и телефонах;
нет лишних кнопок;
быстрый;
бесплатный.
Редактор открывает схемы...
Opencart SEO Web Брендинг Интернет-магазины Корпоративные сайты и блоги Маркетинг Оптимизация и ускорение
Оптимизация загрузки js бандла использующего icon pack’и / Хабр | Веб-студия Nat.od.ua
Оптимизация загрузки js бандла использующего icon pack’и / Хабр
Иконки в проекте часто становятся причиной проблем разбухания размера бандла. Все из-за того что svg-иконки могут быть достаточно объемными.
Если мы загружаем только те иконки, что мы реально используем то это...

Opencart SEO Web Брендинг Интернет-магазины Корпоративные сайты и блоги Маркетинг Оптимизация и ускорение
Фронтенд-новости №11. JQuery живее всех живых, замена CAPTCHA, вариативные шрифты в Figma | Веб-студия Nat.od.ua
Фронтенд-новости №11. JQuery живее всех живых, замена CAPTCHA, вариативные шрифты в Figma
Дайджест новостей и полезных статей из мира фронтенд-разработки за неделю 13–19 июня.
Доступность
Аспекты доступности — семантика, контратность и… тревога?
Спецификации
Замените...

Opencart SEO Web Брендинг Интернет-магазины Корпоративные сайты и блоги Маркетинг Оптимизация и ускорение
Запускаем DOS игру в браузере / Хабр | Веб-студия Nat.od.ua
Запускаем DOS игру в браузере / Хабр
В 2022 году мало кого можно удивить DOS игрой в браузере. Благодаря dosbox они доступны на многих платформах. А поддержка браузера появилась с развитием компилятора emscripten. js-dos один из самых заметных проектов портирования dosbox в...

Opencart SEO Web Брендинг Интернет-магазины Корпоративные сайты и блоги Маркетинг Оптимизация и ускорение
Использование WebAssetsManager Joomla 4 и добавление собственных пресетов с помощью плагина | Веб-студия Nat.od.ua
Использование WebAssetsManager Joomla 4 и добавление собственных пресетов с помощью плагина
В мире фронтенда многие ресурсы (ассеты) связаны между собой. В Joomla никогда не было простого способа указать эту связь, но Joomla 4 изменила эту ситуацию, введя концепцию Web...

