
Opencart SEO Web Брендинг Интернет-магазины Корпоративные сайты и блоги Маркетинг Оптимизация и ускорение
Как мы провели второй русскоязычный Laravel-митап / Хабр | Веб-студия Nat.od.ua
Как мы провели второй русскоязычный Laravel-митап / Хабр
Привет, за клавиатурой Миша Радионов, и я снова расскажу вам про Laravel. Нет, не про тонкости этого фреймворка, а про Laravel-митап, который мы провели в Студии Флаг уже во второй раз.
Немного истории
За 12 лет...
Opencart SEO Web Брендинг Интернет-магазины Корпоративные сайты и блоги Маркетинг Оптимизация и ускорение
Отображаем ACF поля красиво и без кодинга / Хабр | Веб-студия Nat.od.ua
Отображаем ACF поля красиво и без кодинга / Хабр
Плагин Advanced Custom Fields используется в WordPress повсеместно, за свою карьеру я встретил лишь несколько сайтов которые обходились без него (весьма специфические). Большой набор типов полей, хороший интерфейс для...

Opencart SEO Web Брендинг Интернет-магазины Корпоративные сайты и блоги Маркетинг Оптимизация и ускорение
прокачиваем навыки владения CSS / Хабр | Веб-студия Nat.od.ua
прокачиваем навыки владения CSS / Хабр
Архипкин Дмитрий
веб-разработчик в HTDev
Любые навыки прокачиваются опытным путём и упорным изучением – это факт, с которым сложно не согласиться. Изучение языков программирования и каскадных таблиц стилей не являются исключением –...

Opencart SEO Web Брендинг Интернет-магазины Корпоративные сайты и блоги Маркетинг Оптимизация и ускорение
Следим и вычисляем с Vue 3, или Как использовать watchEffect / Хабр | Веб-студия Nat.od.ua
Следим и вычисляем с Vue 3, или Как использовать watchEffect / Хабр
Привет! Меня зовут Алексей, я frontend-специалист SimbirSoft. В этой статье разберем новый метод слежения за реактивными свойствами watchEffect.
С появлением Vue 3 c Composition API стало доступно два...
Opencart SEO Web Брендинг Интернет-магазины Корпоративные сайты и блоги Маркетинг Оптимизация и ускорение
Зачем менять надёжный пароль? Брутфорс и энтропия / Хабр | Веб-студия Nat.od.ua
Зачем менять надёжный пароль? Брутфорс и энтропия / Хабр
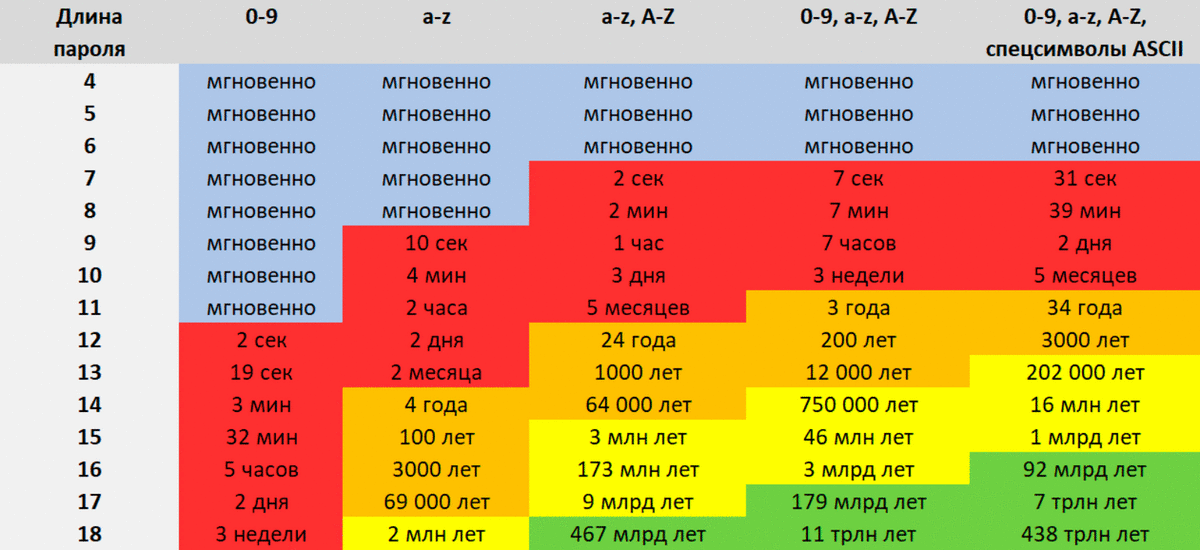
Что такое надёжный пароль? По мере развития технологий за последние десятилетия несколько раз менялись политика, что считать таковым. Мощности для брутфорса становятся всё доступнее, в том числе в облаках, поэтому и...

Opencart SEO Web Брендинг Интернет-магазины Корпоративные сайты и блоги Маркетинг Оптимизация и ускорение
Как использовать QueryParamsHandling в Angular / Хабр | Веб-студия Nat.od.ua
Как использовать QueryParamsHandling в Angular / Хабр
При создании одностраничных приложений URL часто меняется без перезагрузки страницы.
Это может приводить к проблемам при попытке доступа к параметрам запроса из URL. Функция QueryParamsHandling в Angular позволяет...

Opencart SEO Web Брендинг Интернет-магазины Корпоративные сайты и блоги Маркетинг Оптимизация и ускорение
что нас ожидает / Хабр | Веб-студия Nat.od.ua
что нас ожидает / Хабр
В сентябре этого года Microsoft анонсировал TypeScript 4.9 beta. В бета-версии появились любопытные нововведения и исправления: новый оператор, оптимизация производительности, улучшения существующих типов…
Меня зовут Екатерина Семенова, я —...

Opencart SEO Web Брендинг Интернет-магазины Корпоративные сайты и блоги Маркетинг Оптимизация и ускорение
React tips for faster development at scale / Хабр | Веб-студия Nat.od.ua
React tips for faster development at scale / Хабр
Впервые я познакомился с React в 2015 году и вот уже использую его можно сказать повседневно 7 лет. Бесчисленное количество компонентов было написано за это время, React из подающей надежды модной технологии вырос в...

Opencart SEO Web Брендинг Интернет-магазины Корпоративные сайты и блоги Маркетинг Оптимизация и ускорение
как обойти ограничения OpenStreetMaps / Хабр | Веб-студия Nat.od.ua
как обойти ограничения OpenStreetMaps / Хабр
OpenStreetMaps — это Open Source продукт, в котором 9 млн человек со всего Интернета создают свободную карту мира. Также это бесплатная альтернатива Google Картам при коммерческой разработке. Главная проблема такого продукта в...

Opencart SEO Web Брендинг Интернет-магазины Корпоративные сайты и блоги Маркетинг Оптимизация и ускорение
Разработка приложений со 100%-й кастомизацией. Customization Driven Development (CDD) / Хабр | Веб-студия Nat.od.ua
Разработка приложений со 100%-й кастомизацией. Customization Driven Development (CDD) / Хабр
В данной статье я хочу поделиться своим опытом разработки интерфейсов с уровнем кастомизации вплоть до 100% (реальные 100%). При этом сохраняется обратная совместимость и...

