
Сервисная архитектура во Vue 2 | Веб-студия Nat.od.ua
Сервисная архитектура во Vue 2
Да-да, я знаю, Vue 3 находится в stable-версии, и даже Nuxt наконец-то обновился. Но именно 3-й Vue с его provider / inject подтколкнул меня к поиску решения о том, как можно удобно инкапсулировать бизнес-логику во Vue 2.
Введение
Начнем с вопроса «Почему нельзя просто обновиться до Vue 3?». Все просто, некоторые проекты обладают таким уровнем связанности с другими проектами, что это невозможно сделать быстро. Где-то возможно используются специфичные пакеты, которые были написаны только под 2-ю версию Vue. Где-то разработчиков устраивает Vue 2, а даже если бы они и перешли на Vue 3, они продолжали бы писать на Options API (скажу сразу, я не проверяла свое решение на Vue 3, так что не уверена сработает ли такой подход там, но вообще должен).
Как можно инкапсулировать логику
На просторах интернета и участвуя в вопросах, задаваемых в чатах (по типу «Vue.js — русскоговорящее сообщество»), да и просто работая, чаще всего я видела несколько решений. Давайте разберем их плюсы и минусы.
Вынести во Vuex/Pinia/Другой стейт менеджер
На удивление один из самых популярных ответов, как только нужно делиться какими-то данными — вынеси в стор.
Доходит до смешного, человек спрашивал как можно передать строку поиска из компонента в соседний (у них общий родитель). Ему накинули несколько решений, и человек выбрал Vuex, потому что на его взгляд это проще.
Другой пример, на проекте я видела страницу, которая сохраняла временные данные форм (и в какой-то мере кешировала на сессию) с помощью.. Vuex. Я думаю, нет смысла объяснять подробно чем это чревато, но багов там связанных с этим было много, мне пришлось полностью переделать эту страницу.
Pros
-
Часто советуют, легко найти помощь
-
Использование vuex интуитивно понятно
-
Возможно внушает чувство безопасности
-
В целом легко читается, понятно откуда приходят данные
-
Можно получить только те данные, которые тебе нужны в конкретном компоненте
Cons
-
Вызывает баги, если пытаться хранить временные данные (которые должны чиститься, или меняться в зависимости от контекста)
-
Невозможно переиспользовать логику (модуль один на сайт, от этого ты никуда не денешься, дополнительный экземпляр не создашь) только если не сделать 10 одинаковых модулей
-
Используя недолго эту логику, она все равно останется в памяти, хоть и больше не требуется
-
Данные не защищены, любой компонент может изменить их с помощью прямого обращения к state
Миксины
Это второй по популярности метод выноса какой-то общей логики, но если ответ про Vuex частый при проблеме распространения данных, то миксины — это популярный метод выноса логики. Хотя по моим впечатлениям люди начали реже им пользоваться, в силу того что в официальной библиотеке рекомендуют максимально остерегаться этого способа.
Pros
-
опять же интуитивно понятно, выглядит как кусок компонента
-
другого способа интегрировать общий хук, или фреймворко-зависимые элементы особо нет
Cons
-
Если само написание миксина действительно интуитивно понятно, то вот чтение компонента, использующего миксин совершенно нечитабельно. Ты выделяешь переменную, ищешь ее по файлу, а ее просто нет, и вот эту маленькую строчку mixins очень легко пропустить.
-
Легко затереть функциональность миксина, используя случайно те же имена свойств/методов
-
Иногда миксины используют свойства, которые должны быть определены в компоненте, а ты можешь этого не знать
-
Невозможно расшарить данные (только если не положить их во vuex)
-
Подходит только для переиспользования кода, что-то глобальное сделать с помощью миксина не получится
-
Выбрать какие методы/свойства тебе нужны нельзя
Provide / Inject
Это уже не самый популярный способ, не все знают про эту опцию. Многие знают про то, что это есть во Vue 3, но во Vue 2 provide появился еще в версии 2.2.0. Подробнее можно почитать по ссылке.
В целом технология позволяет передать либо объект, либо функцию, возвращающую объект. Так что думаю есть возможность, если поиграться передать тот же экземпляр класса. Но возможно это вызовет определенные проблемы.
Pros
-
Позволяет передавать данные на любую глубину
-
Можно выбрать, что ты будешь инъектить
Cons
-
Требует общего родителя, в худшем случае придется делать это на странице или в App что засоряет код
-
Таким образом не получится переиспользовать код, это больше про распространение данных
-
Если сделать экземпляр класса (каким-то образом, я не пробовала), то ты его себе заберешь целиком, нет возможности выбрать, что тебе надо
-
Не интуитивно и не очевидно, что будет происходить с реактивностью, где менять эти данные, и вообще вызывает много вопросов
Почему я упомянула provide/inject в начале
Когда я писала на Vue 2, у меня даже примерной идеи не было, как бы можно было инкапсулировать логику. Мне казалось, что в том формате, как мы делаем компоненты, это будет по-любому неудобно, непонятно, и как-то костыльно.
Vue 3 с Composition API открыл для меня новую веху, там можно сделать экземпляр класса, полностью обернуть его в reactive, сделать provide прям на этапе создания приложения (т.е. в index.js условном, что было понятно).
Но и это решение меня не до конца устраивало, мне хотелось сделать это как-то по-другому. Пока я об этом думала, я перешла на другой проект, который написан на Vue 2, и это подтолкнуло меня к поиску решения.
Вынести в функции
Этот способ очень хорошо подходит для простых функций, не связанных ни с чем другим, валидаторы или форматтеры. С точки зрения инкапсуляции логики (а обычно в таком случае мы говорим про связный процесс, где происходит несколько этапов в разное время) это не самый подходящий способ.
Pros
-
Легко использовать, импортируешь функцию и используешь
-
Знакомо и узнаваемо
Cons
-
Для связанного процесса приходится передавать данные из одной функции в другую, что ухудшает читабельность
-
Если пытаешься сохранить данные в какой-то переменной вне функций, не будет ясности, что там находится
Глобальные переменные
Во Vue 2 я частенько записывала созданный мной класс, хранящий экземпляр Axios, в глобальные переменные. Это довольно удобно для модуля, который используется повсеместно.
Pros
-
Удобное использование через this
-
Можно в глобальную переменную записать экземпляр класса, что увеличивает ваши возможности
Cons
-
Даже если записать экземпляр класса, то он будет один
-
Непонятно, будут ли данные реактивными, не совсем очевидно
-
Использование через this удобно для тех, кто знает, какие данные в проекте глобальные. Для остальных придется еще догадаться, где искать эту запись, и что же кроется под переменной.
Вынести в класс
Кажется самым удобным методом, но те статьи, которые я находила, предлагали либо сделать singleton, либо делать статические методы и встраивать их подобным образом
methods: {
someAlias() {
Class.someMethodFromClass();
}
}
Такой способ мне не нравится тем, что много мусорных функций, нет понимания как встраивать данные и менять их. Да и вообще так получилось, что я не нашла ни одной статьи, которая бы показывала полноценное решение, учитывая всевозможные случаи.
Поэтому я решила создать это решение сама.
Вводные
Хочется, чтобы можно было создать сервис, который
-
Создавал экземпляр только по запросу, позволял создать несколько экземпляров, мог удалить нужный экземпляр
-
Было понятно откуда пришли данные или методы, чтобы при поиске по файлу названия можно было найти источник
-
Данные должны быть консистентные, при изменении в одном месте, во всех остальных местах они должны стать такими же
-
Если данные используются в компоненте, то должна быть возможность сделать их реактивными, то есть при отображении в template после изменения компонент должен перерендериться
-
Должна быть возможность защитить данные, чтобы менять их можно было только из класса, запретить изменение из компонентов
-
Должна быть возможность менять данные с компонента, установить валидатор для подобных изменений
-
Должна быть возможность получить экземпляр компонента для каких-то специфичных действий, хоть я и не очень это поддерживаю
-
Должна быть возможность встраивать этот класс в любой компонент без обязательства иметь общего родителя
Спойлер
Я смогла реализовать подобную логику, оказалось, это было так просто, что даже смешно. И теперь я хочу рассказать об этом вам и предоставить функции-фабрики для обвязки подобного класса, чтобы вы могли тоже удобно пользоваться классами.
Это 1 часть статьи про реализацию сервиса во Vue 2.
Во 2 части я хочу рассказать о деталях проектирования класса, как работать с разными типами данных, каким образом они встраиваются в компонент и приобретают реактивность, как сделать геттер на свойство/свойства (аналог computed) и передать его в компонент.
В 3 части я расскажу про экземпляры, как регулировать создание и уничтожение, покажу мои функции-фабрики для обвязки класса, как сделать удобную передачу таких свойств в компонент.
Опционально
В 4 части я бы хотела порассуждать о том, какой сервис можно считать хорошим, что стоит выносить в сервис, чтобы не выстрелить себе потом в ногу, как их тестировать и как тестировать компоненты, использующие сервис.
Буду смотреть по вашей реакции, будет ли вам интересно про это прочитать.
Если не хотите ждать, то вот ссылка на репозиторий с рабочим решением, там есть подробные комментарии о реализации. Наиболее интересные файлы: сам класс, и конечно функции для обвязки.
Этот вариант еще в стадии черновика, я готовлю для него документацию. С практикой я буду его дорабатывать, плюс по ходу написания следующих частей я могу вспомнить про какой-то кейс, который не учла.

Как мы провели второй русскоязычный Laravel-митап / Хабр | Веб-студия Nat.od.ua
Как мы провели второй русскоязычный Laravel-митап / Хабр
Привет, за клавиатурой Миша Радионов, и я снова расскажу вам про Laravel. Нет, не про тонкости этого фреймворка, а про Laravel-митап, который мы провели в Студии Флаг уже во второй раз.
Немного истории
За 12 лет существования компании мы прошли разные этапы. Но так или иначе мы пришли к одной мысли — нужно развивать узкий стек технологий, и стать в нем лучшими. Так и произошло с Laravel. Мы постоянно записываем и выкладываем курсы по Laravel на Youtube и делимся пакетами в Open Source. У нас больше десятка бэкендеров, которые пишут только на Laravel, и за это время реализовали более сотни успешных проектов на этом фреймворке.
Так, однажды встал вопрос, а почему бы нам не делиться нашей экспертностью и не проводить Laravel-митап. И вот, год назад, прошел первый митап, в котором выступали в качестве докладчиков наши ребята. Подробнее о первом митапе мы уже писали в блоге. Читайте тут.
Рецепт хорошего митапа
Что вообще такое митап? Митап — это неформальная встреча айтишников для обсуждения рабочих вопросов и обмена опытом. По сути, это — конференция со спикерами, но в более расслабленном формате. Перед нами стояла задача подготовить не только полезное и информативное мероприятие, но и драйвовое, чтобы соскучившиеся айтишники точно смогли оттянуться.
Для начала мы продумали и сделали яркий и цепляющий лендинг, на котором разметили всю нужную информацию, таймлайн и ФОС как для спикеров, так и для зрителей.
Через какое время мы начали получать заявки от спикеров. Один из них откликнулся с Кемеровской области, и был намерен приехать в Екатеринбург ради такого события 🙂 Тогда мы уже поняли, что второй Laravel-митап пройдет на высоком уровне.
Мы начали работать со спикерами, помогать с докладами, оттачивать презентации. Параллельно с этим встал вопрос: чем кормить и поить зрителей. Конечно же, пивом и пиццей. Пицца у нас была от Додо Пиццы, которые выступили в качестве партнера мероприятия. А вот пиво мы заказали от Jaws.
А что делать зрителям в перерывах? Ну конечно общаться со спикерами и играть в кикер. Для чего еще у нас в офисе стоят 4 стола для кикера. Еще мы намутили классного фотографа, который поймал все яркие моменты митапа.
Это что касается подготовки, так а что по спикерам в этом году? Сейчас расскажу про каждый доклад.
Доклад 1. Сергей Сахаров — «Использование пакета Laravel Octane для ускорения работы приложения».
Сергей приехал на митап с города Юрга, Кемеровская область. Как он рассказывает, только увидел анонс, и не раздумывая, купил билеты. И Екатеринбург посетил, и полезным опытом с коллегами поделился 🙂
В своем докладе Сергей рассказал о плюсах и минусах пакета Laravel Octane, особенностях работы, нюансах, которые стоит учитывать при переводе существующего приложения на этот пакет с примерами из практики.
Вот, что Сергей сказал о нашем митапе.
Спасибо за митап и за тёплый приём! После митапа остались только положительные эмоции. У Студии Флаг классная команда профессионалов, которой желаю лёгкого достижения любых целей и вывести Laravel-митап на уровень не ниже Laracon’a 🙂
Доклад 2. Роман Постников — «Laravel + Clean Architecture».
Роман когда-то работал в нашей студии и также выступал спикером на прошлом митапе. В этом году Роман поделился главным принципом «Чистой архитектуры» и рассказал, как вынести весь фреймворк на внешний слой, от которого не будет зависеть бизнес-логика приложения. Такое решение поможет легко тестировать и поддерживать даже самое большое приложение.
Доклад 3. Максим Колмогоров — «Внедряем SSR в проект».
Максим рассказал про технологию SSR и способы ее внедрения в Laravel проект через готовый плагин, или с помощью SSR-фреймворков. Его доклад отметился бурным обсуждением и запомнился шутками и интересной подачей материала Максимом.
Классное мероприятие, прихожу второй раз. Остался очень доволен. Приду третий раз, даже снова выступлю, если позовут. Вообще, у нас в России IT митапы очень извращены всякими штуками по типу: HR, которые навязывают вакансии, тонна ненужной рекламы курсов, некомпетентные спикеры и тому подобное. Здесь все было иначе: программисты собрались и веселятся. Настоящая IT тусовка для своих. Очень рад, что знаком с организаторами, и меня позвали. От себя лишь постарался притащить на мероприятие всех моих знакомых. К слову, они тоже не пожалели, что пришли.
Доклад 4. Алексей Смирнов — «Мутационное тестирование».
Алексей — единственный докладчик от нашей студии. Это сильный и опытный разработчик, который также выступал на митапе в прошлом году.
Для проверки корректной работы кода используются автотесты. Их количество растёт, проект становится проще поддерживать. Но когда тестов в проекте уже достаточно, высокое покрытие может ввести в заблуждение и дать ложные надежды, что всё хорошо протестировано, и разного рода изменения ничего не сломают. Но это не так. В своем докладе Алексей рассказал о том, как избежать проскакивание багов мимо тестов, проверить сами тесты на качество, и при чём тут мутационное тестирование.
Что еще интересного было на митапе
Митап прошел здорово. В нашем офисе собралось около 70 зрителей, а для тех, кто не смог приехать, мы организовали онлайн-трансляцию на YouTube.
Между докладами спикеров зрители активно общались и обменивались опытом. Кто-то устроил мини-турнир по кикеру, а кто-то решил провести пару свободных минут, играя классические композиции на фортепиано. Было видно, что айтишники за время локдауна и удаленки истосковались по нетворкингу и живому общению. Мы продумали все развлечения так, чтобы каждый участник провел перерывы максимально продуктивно и интересно.
В середине мероприятия был организован большой перерыв с пивом и пиццей, во время которого зрители и спикеры завязали новые знакомства, обсудили Laravel и не только.
Завершился митап афтерпати, на которое остались все желающие. После организаторы получили обратную связь, которая мотивирует их на проведение новых, крутых мероприятий для айтишников.
Отзывы зрителей
После митапа мы, конечно же, собрали обратную связь, чтобы в следующий раз было еще круче. Вот некоторые из отзывов, которые нам прилетели.
Спасибо организаторам, что смогли провести такое мероприятие. Это очень радует.
Ведущий огонь! Неформально, просто, весело! Шутейки с интеграционной рекламой хороши! А если серьёзно, доклады на этот раз очень понятные, без занудства, жаль не удалось наших фронтендеров притащить на этот митап
Организация мне понравилась. Доклады не сильно длинные, без лишней воды, как раз чтобы получить необходимое представления о технологии для дальнейшего изучения. Юмор, юмор всегда располагает
Заключение
Такая крутая обратная связь мотивирует нас на проведение еще больших и качественных ивентов. Конечно, мы и дальше продолжим проводить Laravel-митапы, но в планах у нас появились новые идеи, о которых я вам пока рассказывать не буду 🤫
Смотрите онлайн-трансляцию митапа, ставьте лайки и оставляйте комментарии.

Отображаем ACF поля красиво и без кодинга / Хабр | Веб-студия Nat.od.ua
Отображаем ACF поля красиво и без кодинга / Хабр
Плагин Advanced Custom Fields используется в WordPress повсеместно, за свою карьеру я встретил лишь несколько сайтов которые обходились без него (весьма специфические). Большой набор типов полей, хороший интерфейс для админов, обширная документация для разработчиков. Казалось бы, чего проще, вывести поля на фронт сайта. Но на практике это делается довольно некрасиво, и занимает гораздо больше времени, чем можно было бы ожидать. Я расскажу как вывести любые ACF поля на фронт без кодинга (и без visual page builders), очень быстро и не превращая код темы в черную дыру спагетти код.
Проблемы кодинга
Самый простой пример — вывод поля. Казалось бы, что может быть проще? Но в процессе разработки «всплывают» проблемы.
Проблема №1. Постоянное посещение ACF группы в админке
Во первых это имя поля. По названию (label) далеко не всегда (а на практике — никогда) можно узнать имя поля, и каждый раз приходится идти в список групп, находить текущую и смотреть имя поля. Ладно, с этим мы разобрались. Теперь что по поводу возвращаемого значения? Хорошо если мы говорим про текстовое поле. А если это изображение, select или post? А тут у нас оказывается полный зоопарк, кроме того что у нас есть множество типов (это же хорошо) у каждого типа есть разные return_format-ы. А это значит что нужно в той же группе проверять настройки конкретного поля. Хорошо если возвращается ID или объект (WP_Post). А если массив? (например опция изображения). Какие там ключи? Конечно, когда выводишь ACF поля ежедневно, их имена всегда в памяти, а если был занят другим?
Проблема №2. Постоянное посещение ACF документации
Таким образом мы подходим ко второй проблеме. Чтобы узнать детали return_format-а, ключи возвращаемого массива или как получить label поля вместе со значением приходится часто наведываться в ACF документацию для соответствующего типа поля. Благо документация хорошая. Но время таки уходит.
Проблема №3. Синхронизация изменений
На практике изменения в существующие поля вносятся гораздо чаще чем можно предположить. Например изменяется return_format (не говоря уже про имя и тип поля, и такое бывает) и приходится делать поиск по всему коду темы, чтобы найти куски кода что получают и используют это поле, так что это становится настоящим кошмаром (и кто-то мог использовать в одном случае двойные кавычки, а кто-то одинарные, и имя то поля может быть кратким и не уникальным, пойди найти всех).
Проблема №4 (Опциональная). Спагетти код
Чего только тут мои глаза не видели. Особенно когда вносятся правки, а не создается страница с нуля. Про кучу спагетти кода в шаблонах, где нельзя понять (даже при большом желании) где начало и где конец я просто не упоминаю. В лучшем случае разработчик прямо в functions.php добавляет регистрацию шорткода и в нем делает вывод нужных полей, и далее устанавливает шорткод в нужное место. (И откровенно говоря, когда вносишь правки в такие «веселые» темы, нет ни времени ни желания что либо менять, просто рядом создаешь еще один и стараешься забыть поскорее все что ты видел) Проблема с таким functions.php что в один день это становится файлом в 3-7 тысяч строк кода, без структуры, без начало и конца. И совсем не понятно, зачем нужен определенный кусок кода, где это используется. Про последствия такого подхода я умолчу, думаю ужасы редактирования, отладки и оптимизации всплывут у всех видевших подобное.
Проблема №5. Стилизация и CSS конфликты
Разметка полей обычно делается на скорую руку и классы в разметке используются из тех, что первые приходят на ум. (К сожалению про BEM слышали далеко не все, а используют еще меньше). В худшем случае стили для этих полей будут добавлены глобально, в лучшем только для целевой страницы. В первом случае будет проблема неиспользуемого CSS кода (привет нулевой Google Page Speed) и конфликтов с другими элементами (названия классов то общие), во втором — проблема переиспользования на других страницах.
Суммируя вышесказанное
Эти проблемы замедляют время разработки и внезапно, чтобы вывести 4 поля у разработчика уходит не 1 минута, а 10, и кроме созданного вывода также создаются множество проблем для того, кто это будет править/поддерживать.
Решение. Вывод полей без кодинга с помощью шорткодов
Как же обойти эти проблемы? Речь сейчас пойдет не про встроенные шорткоды. К сожалению они подходят только для примитивных полей (строка, число) и кроме того они выводят только значения, разметку по прежнему надо создавать самим.
Речь про новый (и бесплатный) ACF Views плагин, который предоставляет шорткоды для вывода полей. И если первое что вам пришло в голову — шорткод для вывода значения по имени поля — вы ошиблись.
ACF Views плагин позволяет вам создавать Views (внутри обычные CPT items) в которых вы:
-
Выбираете ACF поле для вывода
(одно или несколько, можно с разных групп. Выбор через обычный select) -
Сохраняете View, копируете шорткод
(из серии ) -
Используете шорткод где угодно
(Выбранные поля должны быть заполнены на том объекте, где устанавливается шорткод, будь то страница или CPT объект. Или нужно использовать object-id аргумент шорткода, чтобы указать id объекта, откуда брать эти поля)
Во время выполнения шорткод будет обработан плагином, и заменен HTML разметкой, которая будет сгенерированна (автоматически) в зависимости от типа поля и значения поля. (Плагин поддерживает все типы полей, включая изображния и select-ы) Это упрощает задачу в разы, и решает вышеупомянутые проблемы:
Проблема №1. Постоянное посещение ACF группы в админке
Вы выбираете поле (или поля) из списка, не нужно искать имя, не нужно заботится о типе и return-format-е.
Проблема №2. Постоянное посещение ACF документации
Плагин автоматически генерирует разметку для полей в зависимости от типа и return-format-а полей, нам заботиться об этом больше не нужно.
Проблема №3. Синхронизация изменений
Плагин сохраняет id выбранных полей и получает информацию о полях от ACF динамически. Это значит что мы можем менять поле как угодно, включая имя и тип, не говоря про return-format и абсолютно никаких обновлений от нас не потребуется. Разметка будет всегда актуальной.
Проблема №4 (Опциональная). Спагетти код
Теперь никакого хаоса в functions.php. Отдельный пункт меню в WordPress админке со списком всех View (вы можете задавать им имена и краткие описания), с поиском по ним.
Проблема №5. Стилизация и CSS конфликты
Теперь это мой любый пункт. Разметка генерируется в BEM стиле, так что больше никаких конфликтов. Кроме этого, каждое View имеет свое поле для CSS кода, где вы можете написать стили для этих полей. Этот CSS: a) никогда не создаст конфликтов (BEM стиль + используется id этой View) b) появляется только на страницах где используется текущая View, так что никаких глобальных стилей.
Суммируя вышесказанное
Используя ACF Views плагин (бесплатный) можно вывести любые ACF поля на фронт очень быстро и не создавая проблем для того, кто это будет править/поддерживать. Подробнее узнать о плагине можно на его официальном сайте, где вы сможете найти ссылку на их YouTube канал, который наглядно демонстрирует использование плагина.
У опытных разработчиков наверняка возникнет вопрос, а что по накладным расходам? Это обертка и вероятно это гораздо медленнее чем обычный код. А вот и нет. Авторы плагина уделили особое внимание вопросам производительности (например использовали JSON в вместо мета полей для хранения Views данных) и даже опубликовали тест, который показывает что разницу с кодом будет невозможно заметить на глаз.
Ниже я привожу несколько скриншотов плагина которые я сделал, чтобы вы могли увидеть, как выглядит UI плагина. Надеюсь эта статья была полезной для вас.
P.S. Функциональность данного плагина выходит за рамки этой статьи. Если вам будет интересно, то я расскажу что еще можно сделать используя данный плагин. (Например выбирать и отображать посты, к примеру отобразить 4 последних WooCoomerce продукта без кодинга)

прокачиваем навыки владения CSS / Хабр | Веб-студия Nat.od.ua
прокачиваем навыки владения CSS / Хабр
веб-разработчик в HTDev
Любые навыки прокачиваются опытным путём и упорным изучением – это факт, с которым сложно не согласиться. Изучение языков программирования и каскадных таблиц стилей не являются исключением – достичь высоких результатов в этом вопросе удастся только благодаря регулярной практике.
Владея знаниями по вёрстке, можно достичь поставленных целей и перейти на следующую ступень профессионализма. В этой статье я расскажу, какие материалы мы с коллегами используем в своей работе: уверен, эта информация будет полезна разработчикам на CSS.
На базовом уровне
Цель: Помнить все свойства в CSS. Достигается примерно за 300 часов
Что изучать?
В первую очередь, синтаксис. А дальше по порядку:
-
Блочная модель https://doka.guide/css/box-model/
-
Специфичность https://doka.guide/css/specificity/
-
Принцип каскада https://doka.guide/css/cascade/
-
Методологии именования классов
Доклад: https://www.youtube.com/watch?v=1VM-vEItVeA&ab_channel=moscowcss
Презентация https://wsd.events/2016/10/01/pres/css-methodologies.pdf -
Позиционирование https://fls.guru/cssposition.html
-
Псевдоэлементы https://doka.guide/css/pseudoelements/ и псевдоклассы https://doka.guide/css/pseudoclasses/
-
Единицы измерения css https://fls.guru/css-units.html
-
Фон https://fls.guru/cssbackground.html https://yoksel.github.io/css-patterns/
-
Способы выравнивания элементов https://www.internet-technologies.ru/articles/centrirovanie-v-css-polnoe-rukovodstvo.html
-
Сетки Flex.
Теория: https://tpverstak.ru/flex-cheatsheet/Практика: https://the-echoplex.net/flexyboxes/ -
Основы SVG https://svgontheweb.com/ru/#preparation https://svgontheweb.com/ru/#implementation
-
Transform https://fls.guru/transform.html https://yoksel.github.io/pages/transform-functions/
-
Шрифты https://html5book.ru/css-shrifty/ https://doka.guide/css/font-face/Подробно о шрифтах: https://github.com/urfu-2015/verstka-lectures/blob/master/text/text.mdВариативные шрифты: https://yoksel.github.io/opentype-variable-fonts/
-
Дефолтные стили браузера: reset, normalize. https://htmlacademy.ru/blog/html/short-13https://htmlacademy.ru/blog/html/about-normalize-css
-
Валидное написание кода – по стандартам Консорциума Всемирной паутины (W3C). Проверить можно с помощью валидатора.
-
Стиль кода, к примеру:https://codeguide.academy/html-css.html#css
Как практиковаться?
С помощью платформ, например:
Для тренировки и визуализации небольшого участка кода применяются редакторы кода:
Где брать недостающую информацию?
Информацию по свойствам берём через онлайн-справочники:
На профессиональном уровне
Цель: Повысить скорость работы и использовать тонкости CSS на практике. Достигается примерно за 1000 часов.
Что изучать?
-
Адаптивная вёрстка https://doka.guide/css/media/
Теоретические примеры: https://tpverstak.ru/adaptive-cheatsheet/ -
Вёрстка под PixelPerfect https://htmlacademy.ru/blog/html/pixel-perfect
-
Особенности отображения стилей в разных браузерах
-
Препроцессоры SASS, Less, Stylus и постпроцессор PostCSS
-
Сетки Grid.
Теория: https://tpverstak.ru/grid/
Практика: https://alialaa.github.io/css-grid-cheat-sheet/ -
Работа с легаси (к примеру, float)
-
Продвинутые селекторы https://doka.guide/css/child/
http://css.yoksel.ru/nth-child/ -
Продвинутые фишки CSS
Например, z-index https://developer.mozilla.org/ru/docs/Web/CSS/z-index -
CSS-функции
https://developer.mozilla.org/en-US/docs/Web/CSS/CSS_Functions
https://dev.to/balaevarif/css-gio -
Стилизация скролла https://only-to-top.ru/blog/coding/2020-01-31-stilizaciya-skrolla-css.html
https://doka.guide/css/scroll-behavior/
https://doka.guide/css/scroll-padding/ -
CSS-анимация https://fls.guru/cssanimation.html
https://animista.net/play/text -
Углублённое изучение SVG https://svgontheweb.com/ru/
https://yoksel.github.io/svg-decoration/ -
SVG-анимация https://svgontheweb.com/ru/#animating
-
Библиотеки CSS:
Tailwind
Bootstrap
Foundation
Как практиковаться?
Самый эффективный способ – работая с макетами. Макеты можно найти в телеграм-каналах:
Или на платформах:
Где брать недостающую информацию?
В онлайн-справочниках:
https://doka.guide/css/
https://developer.mozilla.org/ru/docs/Web/CSS
В книгах:
-
Кит Грант «CSS для профи»
-
Дэвид Макфарланд «Большая книга по CSS»
-
Грег Сидельников «Наглядный CSS»
-
Леа Веру «Секреты CSS. Идеальные решения ежедневных задач»
На экспертном уровне
Цель: полная экспертность в вопросе и стремление развить свои навыки до высочайшего уровня. Достигается постоянным изучением CSS и практикой, измерение в часах невозможно.
Что изучать?
Фундаментальные механизмы CSS: обработка значений (value processing), каскад и наследование.
Оригинальная документация W3C https://www.w3.org/Style/CSS/Overview.en.html
Что практиковать?
Всё, включая апробацию новых фишек.
Где брать недостающую информацию?
Чтобы быть в курсе последних новостей:
-
Отслеживайте выход новых фишек в обновлениях браузеров
-
Читайте специализированные ресурсы, например, CSS-live
В заключении
Для человека, который только начинает изучать программирование, путь от первого знакомства с основами вёрстки до создания «одностраничника» без адаптивной версии займёт в среднем 70 часов. Однако работа верстальщика может включать не только создание лендингов, но и работу над масштабными проектами, такими, как, например, корпоративные порталы для федеральных компаний. Удержать в голове огромное количество знаний об особенностях CSS – очень сложно, плюс, из-за регулярного обновления версий браузеров добавляются новые свойства, функции, дорабатываются уже имеющиеся данные и появляются свежие подходы к вёрстке. Именно поэтому специалист, хорошо владеющий базой, всегда сможет найти для себя новые интересные грани в этой сфере и перспективы для развития своего профессионального потенциала.

Следим и вычисляем с Vue 3, или Как использовать watchEffect / Хабр | Веб-студия Nat.od.ua
Следим и вычисляем с Vue 3, или Как использовать watchEffect / Хабр
Привет! Меня зовут Алексей, я frontend-специалист SimbirSoft. В этой статье разберем новый метод слежения за реактивными свойствами watchEffect.
С появлением Vue 3 c Composition API стало доступно два метода слежения — watch и watchEffect. Если «старый» метод watch всем хорошо знаком и не должен вызывать затруднений у Vue-разработчиков, то новый метод стоит изучить подробнее. Материал будет полезен разработчикам, переходящим с Vue 2 на Vue 3 и всем «вьюшникам», которые еще не разобрались с этим методом.
Composition API предоставляет нам два разных метода слежения за реактивными свойствами — watch и watchEffect. Они похожи, но все же каждый полезен в определенных случаях. Рассмотрим, какие сходства и различия существуют у этих методов:
Общее
Отличия
● следят за изменениями зависимостей
● выполняют побочные эффекты в отдельной функции коллбэка
● предоставляют способ остановки слежения
● watch (без immediate) может использоваться для ленивого запуска побочных эффектов (watchEffect всегда отрабатывает немедленно после монтажа компонента)
● watchEffect автоматически следит за изменениями любых состояний (может быть несколько переменных для отслеживания)
● watch обеспечивает доступ к текущим и предыдущим значениям
Это были основные отличия, о других мы расскажем ниже.
Слежение за объектами и массивами в watchEffect
WatchEffect может отслеживать только адрес памяти реактивного объекта. Изменение элементов массива или свойств объекта не изменит адрес памяти и, следовательно, не вызовет срабатывания метода watchEffect:
При нажатии на кнопку add видим, что данные в массив добавляются, но watchEffect отрабатывает только один раз. WatchEffect всегда срабатывает только один раз после монтажа компонента, в watch нам приходилось указывать для этого immediate — true:
Нам нужно преобразовать реактивный объект обратно в массив с помощью spread-оператора:
{{ target }}
Теперь наш watchEffect успешно отрабатывает:
Для слежения за объектами будем использовать toRefs():
{{ data }}
Вызов функции stop() остановит действие watchEffect:
Параметры watchEffect
Метод watchEffect принимает два аргумента. Первый — это коллбэк-функция. Второй — объект конфигурации:
watchEffect(
() => {},
{
flush: ‘post’,
onTrack(e) {
debugger
},
onTrigger(e) {
debugger
}
})
Свойство flush определяет, запускается ли метод watchEffect до, после или во время повторного рендеринга страницы:
flush: ‘pre’ | ‘post’ | ‘sync’
По умолчанию созданные пользователем коллбек-функции наблюдателя вызываются до обновления компонентов Vue. Это означает, что если вы попытаетесь получить доступ к DOM внутри коллбек-функции наблюдателя, DOM будет в состоянии до того, как Vue применит какие-либо обновления.
Дополнительный объект настроек с опцией flush (значение по умолчанию — ‘pre’):
let stop = watchEffect(callback, {
flush: ‘pre’
})
Опция flush также может принимать значение ‘sync’, которое принудительно заставит эффект всегда срабатывать синхронно. Однако такое поведение неэффективно и должно использоваться только в крайних случаях:
watchEffect(callback, {
flush: ‘sync’
})
Если вы хотите получить доступ к DOM в коллбек-функции наблюдателя после того, как Vue его обновил его, вам нужно указать flush: ‘post’:
watchEffect(callback, {
flush: ‘post’
})Отладка watchEffect
Можно использовать опции onTrack и onTrigger для отладки поведения наблюдателя:
-
onTrack вызывается, когда реактивное свойство или ссылка начинает отслеживаться как зависимость;
-
onTrigger вызывается, когда коллбэк наблюдателя вызван изменением зависимости.
Оба коллбэка получают событие отладчика с информацией о зависимости, о которой идет речь. Обратите внимание, опции onTrack и onTrigger работают только в режиме разработки.
Аннулирование побочных эффектов
Иногда в функции наблюдателя могут быть асинхронные побочные эффекты, которые требуют дополнительных действий при их аннулировании (то есть в случаях, когда состояние изменилось до того, как эффекты завершились). Для таких случаев функция эффекта принимает функцию onInvalidate. Она будет использоваться для аннулирования выполненного и вызываться в следующих случаях:
-
когда эффект будет вскоре запущен повторно;
-
когда наблюдатель остановлен (то есть когда компонент размонтирован, если watchEffect используется внутри setup() или хука жизненного цикла).
{{ data }}
Снова запустим наше приложение:
Видим, что сначала отработала основная коллбек-функция, и в консоли вывелось basic function.
Если мы нажмем на кнопку stop, то сработает функция onInvalidate:
Если нажать на кнопку change title, то вначале выполнится функция onInvalidate, а затем основная функция. При изменении свойств onInvalidate будет всегда срабатывать первой:
Практическое применение watchEffect
Мы будем отменять запросы axios, если входные данные изменились, и старые данные больше не актуальны:
Функция setType изменит значение переменной type в зависимости от параметра, который был принят. WatchEffect следит за изменением переменной type, и при ее изменении делает запрос на получение постов или альбомов. Заметьте, мы нигде изначально не инициализируем запрос, поскольку watchEffect срабатывает один раз сразу при загрузке страницы:
Установим скорость сети в Slow 3G. И будем быстро переключаться по кнопкам load post и load alboms. Мы увидим, что запросы, которые больше не актуальны, отменяются.
Резюме
Мы разобрались с методом наблюдения за реактивными сущностями с помощью watchEffect.
Что следует запомнить о методе watchEffect:
-
он всегда срабатывает один раз после монтажа компонента;
-
он может отслеживать несколько переменных;
-
если вы хотите отслеживать изменения после обновления компонента, используйте опцию flush: ‘post’;
-
функция onInvalidate всегда срабатывает перед основной функцией;
-
для слежения за массивами используйте спред-оператор, а для слежения за объектами — функцию toRefs().
Подписывайся на наши соцсети! Авторские материалы для frontend-разработчиков мы также публикуем в ВК и Telegram.
Зачем менять надёжный пароль? Брутфорс и энтропия / Хабр | Веб-студия Nat.od.ua
Зачем менять надёжный пароль? Брутфорс и энтропия / Хабр
Что такое надёжный пароль? По мере развития технологий за последние десятилетия несколько раз менялись политика, что считать таковым. Мощности для брутфорса становятся всё доступнее, в том числе в облаках, поэтому и требования к энтропии паролей повышаются — в 2022 году рекомендуется использовать спецсимволы, цифры, буквы в разных регистрах, с общей длиной минимум 11 символов.
Недавно в индустрии информационной безопасности поднялась дискуссия на тему смены паролей. В частности, появились рекомендации против периодической смены паролей. Логика в том, что пользователям сложнее учить новые пароли каждую неделю, чем запомнить один большой и сложный пароль. В 2017 году рекомендации против смены паролей опубликовала организация NIST, отвечающая за принятие стандартов парольной защиты.
Рекомендации NIST
Пароль представляет собой шаблон, слово, комбинацию или другой тип информации, который предположительно известен только пользователю и может быть проверен для подтверждения личности пользователя.
Стандарты и определения о парольной защите изложены в Специальной публикации NIST 800-63B, раздел 5.1.1.2 «Запоминаемые секретные верификаторы» (NIST, 2017).
В 2017 году NIST официально заявила, что обязательная смена пароля на самом деле значительно снижает общую безопасность системы паролей и не должна использоваться. Это объясняется в вопросах B05 и B06 в разделе FAQ документации NIST к обновлённым специальным публикациям (NIST, 2020).
Но на самом проведено крайне мало исследований, подтверждающих тезис NIST о снижении энтропии паролей при их периодической смене. Давайте разберёмся, так ли это на самом деле.
Энтропия и брутфорс
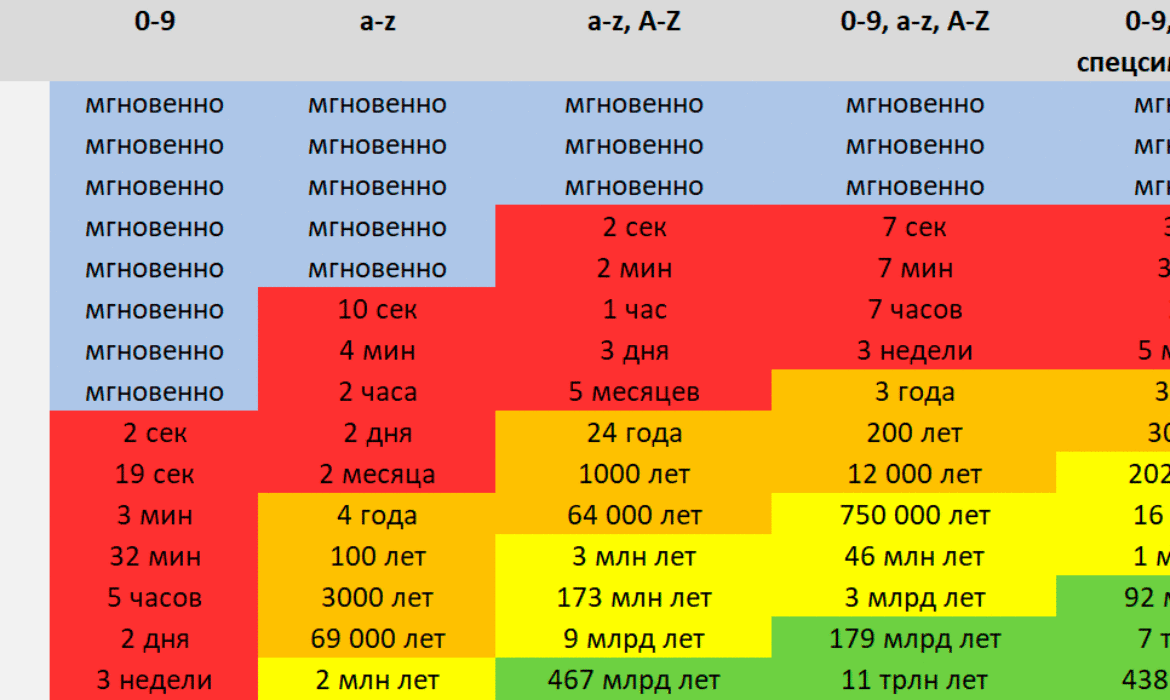
Для вычисления энтропии (E) пароля используется формула
Расчёт количества попыток (G), необходимых для подбора пароля с вероятностью 50%, производится по формуле
- S — размер пула уникальных символов. Некоторые составляющие пула:
- цифры (0-9): 10
- строчные символы латинского алфавита (a-z): 26
- строчные и прописные символы латинского алфавита (a-z, A-Z): 52
- набор символов ASCII (a-z, A-Z, символы, space): 95
- L — длина пароля
Чем выше энтропия — тем лучше, а по современным меркам достаточной считается энтропия 36 бит. Например, пароль типа
S@mp1ePas$word
состоит из строчных и прописных букв, цифр и специальных символов ASCII длиной 14 символов. Такая комбинация даёт размер пула 95, и по формуле это соответствует примерно 4,87×10
27
возможным комбинациям пароля.
Энтропия такого пароля будет рассчитана как , то есть примерно 91,98 бит. С таким значением энтропии мы можем примерно рассчитать, сколько попыток в среднем понадобится, чтобы подобрать пароль (брутфорс 50% всех возможных вариантов). По формуле мы получаем 291,98-1, то есть примерно 2,44×1027 случайных попыток.
Это общее описание метода. В реальности злоумышленник может значительно уменьшить количество попыток с помощью словаря. Для сохранения нормальной энтропии критически важно генерировать случайные пароли в специальном программном обеспечении со стойким ГПСЧ, а не вручную.
Но в целом в индустрии принято мнение, что энтропия пароля, вычисленная по такой методике, коррелирует с его безопасностью.
Для сравнения, у пароля длиной восемь символов из строчных букв энтропия всего лишь 37,6 бит, что даёт нам среднее количество попыток 104,2 млрд. Если предположить, что компьютерная система перебирает более ста миллиардов вариантов в секунду, то такой пароль она взломает практически мгновенно даже без помощи словаря.
Периодическая смена паролей повышает энтропию
Группа исследователей из Университета Роберта Морриса (США) задалась вопросом, насколько эффективной является периодическая смена паролей. В частности, они решили проверить, насколько понижается или повышается энтропия в этом процессе.
Исследователи поставили небольшой эксперимент, в котором согласились участвовать 51 доброволец из тематических сообществ r/PCMasterRace, r/SysAdmin и r/CyberSecurity, где общаются энтузиасты компьютерных технологий.
Краткое описание эксперимента:
- Участников попросили создать аккаунт на сайте эксперимента и придумать произвольный пароль от 2 до 160 символов.
- Затем они дважды в неделю в течение двух месяцев входили в учётную запись. Вход был необходим, чтобы проверить, помнят ли участники свой пароль и могут ли они использовать его в течение длительного периода времени.
- В каждую пятницу пользователям предлагалось выполнить задание в зависимости от их подгруппы. Членам группы А для выполнения задания нужно было просто войти в систему без смены пароля. Членам группы В предлагалось сменить пароль каждую пятницу, а членам группы С — каждую вторую пятницу.
Система была запрограммирована на автоматическую регистрацию всех попыток входа в систему, как успешных, так и неуспешных. Система также автоматически записывала все значения энтропии пароля при каждом обновлении или сбросе пароля. Эти показатели были разработаны для того, чтобы зафиксировать, была ли у какой-либо конкретной группы более высокая частота неудачных попыток входа в систему или других ошибок при входе, а также для отслеживания участия пользователей в исследовании с течением времени.
Был написан скрипт для безопасного вычисления энтропии паролей на хосте без раскрытия или сохранения фактического значения пароля в открытом виде.
По окончании эксперимента получены следующие результаты энтропии (до конца эксперимента продержались 28 человек):
Финальный опрос пользователей из трёх контрольных групп показал, что примерно половина из них использует парольный менеджер, а каждый третий использует предсказуемый паттерн при создании нового пароля.
Тем не менее авторы делают вывод, что периодическая смена пароля скорее повышает, а не понижает их энтропию, как предполагала NIST. Хотя с учётом ограниченного размера выборки, для подтверждения найденных закономерностей необходимо провести дополнительные исследования.
Результаты исследования опубликованы в апреле 2022 года в журнале «Проблемы информационных систем» (том 23:2, стр. 29-41, doi: 10.48009/2_iis_2022_10).

Как использовать QueryParamsHandling в Angular / Хабр | Веб-студия Nat.od.ua
Как использовать QueryParamsHandling в Angular / Хабр
При создании одностраничных приложений URL часто меняется без перезагрузки страницы.
Это может приводить к проблемам при попытке доступа к параметрам запроса из URL. Функция QueryParamsHandling в Angular позволяет решить эту проблему. QueryParamsHandling — это стратегия маршрутизации, позволяющая разработчикам управлять способом обработки параметров запроса при изменении URL.
По умолчанию при изменении URL Angular сбрасывает параметры запроса. Однако благодаря QueryParamsHandling разработчики могут сохранять или объединять параметры запросов при изменении URL.
Существует множество преимуществ использования QueryParamsHandling в Angular-приложениях.
Во-первых, эта функция позволяет разработчикам иметь больший контроль над поведением приложения.
Во-вторых, она упрощает отладку и тестирование приложений, поскольку параметры запросов всегда будут согласованными.
В этой статье я вкратце познакомлю вас с QueryParamsHandling и его типом в Angular.
▍ План изучения
- Что такое QueryParamsHandling?
- Типы или значения QueryParamsHandling
- Пример работы QueryParamsHandling по умолчанию
- Пример объединения параметров QueryParamsHandling
- Пример сохранения параметров QueryParamsHandling
- Подведение итогов
Что такое QueryParamsHandling?
QueryParamsHandling — это встроенная функция маршрутизации Angular, позволяющая разработчикам выбирать, как должны обрабатываться параметры запросов при создании или сопоставлении маршрутов.
Она может быть полезна для таких вещей, как создание ссылок, сохраняющих состояние формы, или для отслеживания истории пагинации.
При создании одностраничных приложений иногда нам требуется возможность управлять тем, как обрабатываются параметры запросов. По умолчанию Angular просто передаёт параметры запросов маршруту.
Однако иногда нам нужна возможность указать, должен ли параметр запроса быть опциональным или обязательным. Именно в этом нам поможет опция QueryParamsHandling.
Типы или значения QueryParamsHandling
Можно использовать три значения QueryParamsHandling:
- Merge (слияние): это опция по умолчанию, она просто объединяет новые параметры запросов с существующими параметрами запросов, которые уже есть в URL.
- Preserve (сохранение): эта опция сохраняет все параметры запросов, находящиеся в URL, и не добавляет новых.
- Replace (замена): эта опция заменяет все имеющиеся параметры добавляемыми новыми.
По умолчанию
QueryParamsHandling использует опцию «merge», означающую, что любые параметры запросов, не указанные в определении маршрута, будут игнорироваться.
Однако разработчики могут выбрать опцию QueryParamsHandling «preserve», это сохранит все параметры запросов из текущего URL при создании или сопоставлении маршрутов.
Кроме того, разработчики могут выбрать в QueryParamsHandling опцию «empty», что будет удалять все параметры запросов из URL при создании или сопоставлении запросов.
QueryParamsHandling по умолчанию
В Angular есть встроенный способ обработки параметров запросов в приложениях. По умолчанию при использовании маршрутизатора для перехода на новую страницу все параметры запросов сохраняются.
Часто нам требуется именно такое поведение, так как оно позволяет нам сохранять состояние между перезагрузками страниц и переходами.
Однако иногда нам может потребоваться игнорирование или сброс параметров запросов при навигации.
Пример работы QueryParamsHandling по умолчанию:
import { Component, Input } from «@angular/core»;
@Component({
selector: «hello»,
template: `
Default component
`,
styles:
})
export class DefaultComponent {}
Пример можно посмотреть на
stackblitz
.
Слияние при помощи QueryParamsHandling
Merge в QueryParamsHandling — это новая возможность Angular, позволяющая лучше управлять параметрами запросов при маршрутизации. Эту функцию можно использовать для упрощения работы с параметрами запросов в вашем приложении.
Merge в QueryParamsHandling можно использовать для автоматического слияния параметров запросов из родительского в дочерний маршрут. Это может быть полезно, когда вы хотите унаследовать параметры запросов из родительского маршрута, но в то же время добавить новые параметры запросов к дочернему маршруту.
Пример слияния QueryParamsHandling:
import { Component, Input } from ‘@angular/core’;
@Component({
selector: ‘a’,
template: `
>router-outlet<>/router-outlet<
>button k2:=»» queryparams=»» queryparamshandling=»merge» routerlink=»b» v2=»»<
Go to b with queryParamsHandling='merge'
>/button<
>br /<
`,
styles: ,
})
export class AComponent {
@Input() name: string;
constructor() {
console.warn(' initialised');
}
}
Пример можно посмотреть на
stackblitz
.
Сохранение параметров при помощи QueryParamsHandling
При создании приложения на Angular по умолчанию маршрутизатор при навигации создаёт новый экземпляр компонента. В большинстве случаев это подходит, но иногда вам нужно сохранять состояние компонента при навигации.
Это можно сделать при помощи опции QueryParamsHandling в конфигурации маршрутизатора.
QueryParamsHandling Preserve полезна для таких вещей, как пагинация, когда вам нужно сохранять номер текущей страницы при навигации. Также эта опция полезна для сохранения введённых в формы значений при перемещении между компонентами.
Однако использование QueryParamsHandlingPreserve обладает некоторыми недостатками. Один из них заключается в том, что оно может вызывать проблемы в истории браузера.
Второй заключается в том, что опция может усложнить тестирование и отладку приложения. В целом, её лучше использовать умеренно и только в случае абсолютной необходимости.
Пример сохранения при помощи QueryParamsHandling:
import { Component, Input } from ‘@angular/core’;
@Component({
selector: ‘a’,
template: `
`,
styles: ,
})
export class AComponent {
@Input() name: string;
constructor() {
}
}
Пример можно посмотреть на
stackblitz
.
Подведём итог
QueryParamsHandling — это отличный способ управления параметрами в URL при помощи Angular. С помощью этого способа можно легко добавлять, удалять и изменять параметры в URL.
Он упрощает отслеживание параметров и помогает поддерживать их актуальность.
У использования queryParamsHandling в Angular есть множество преимуществ. Эта функция помогает более эффективно управлять параметрами URL, а также способна повысить читаемость кода.
Кроме того, queryParamsHandling может помочь избежать потенциальных ошибок в коде.
Telegram-канал с полезностями и уютный чат

что нас ожидает / Хабр | Веб-студия Nat.od.ua
что нас ожидает / Хабр
В сентябре этого года Microsoft анонсировал TypeScript 4.9 beta. В бета-версии появились любопытные нововведения и исправления: новый оператор, оптимизация производительности, улучшения существующих типов…
Меня зовут Екатерина Семенова, я — фронтенд-разработчик в Surf. Давайте вместе разберём самые интересные фичи этого анонса.
Новый оператор satisfies
TL;DR Позволяет делать неоднородные наборы типов более гибкими.
Чтобы понять, зачем нужен оператор satisfies, рассмотрим пример переменной-записи, где данные имеют смешанный характер. Положим, что значения этой записи могут быть как строками, так и числами.
type ComponentKey = ‘component1’ | ‘component2’ | ‘component3’;
const data: Record
component1: 0,
component2: »,
component3: 42,
};
const firstResult = data.component1 + 42;
const secondResult = data.component2.toUpperCase();
Если мы попытаемся работать с объектом data далее, неизбежно наткнёмся на ошибки типов:
Operator ‘+’ cannot be applied to types ‘string | number’ and ‘number’.
Property ‘toUpperCase’ does not exist on type ‘string | number’.
Property ‘toUpperCase’ does not exist on type ‘number’.
Это объясняется тем, что number | string — это объединение. TypeScript разрешает операцию над объединением только в том случае, если она действительна для каждого члена объединения.
TypeScript 4.9 beta предлагает выход: использовать новый оператор satisfies, который позволит безболезненно указывать, какому именно типу удовлетворяет объект.
type ComponentKey = ‘component1’ | ‘component2’ | ‘component3’;
const data = {
component1: 0,
component2: »,
component3: 42,
} satisfies Record
const firstResult = data.component1 + 42;
const secondResult = data.component2.toUpperCase();
Компиляция проходит без ошибок. Попробуем поменять значение в component2, чтобы убедиться, что новый оператор действительно приводит объект к нужному типу:
type ComponentKey = ‘component1’ | ‘component2’ | ‘component3’;
const data = {
component1: 0,
component2: 44,
component3: 42,
} satisfies Record
const firstResult = data.component1 + 42;
const secondResult = data.component2.toUpperCase();
И, как и ожидалось, увидим ошибку:
Property ‘toUpperCase’ does not exist on type ‘number’.
Таким образом мы сохраняем контроль над типами, и работа с записями становится удобнее.
Подробнее про оператор, примеры использования, спорные моменты
Умный in
TL;DR В операторе in станет меньше ошибок при сужении типов.
Оператор in в JavaScript проверяет, существует ли свойство у объекта. Это удобно для данных, чей тип мы не знаем: например, для данных файлов конфигураций.
В TypeScript оператор in часто используется, чтобы проверить, входит ли свойство в объект определённого типа. Пример:
interface Bird {
fly(): void;
layEggs(): void;
}
interface Fish {
swim(): void;
layEggs(): void;
}
function isFish(creature: Fish | Bird): creature is Fish {
return ‘swim’ in creature;
}
isFish — это предикат, который определяет принадлежность параметра creature типу Fish. Для этого выполняется проверка: если свойство swim содержится в объекте, то очевидно, что параметр creature относится к типу Fish.
Возвращаемый тип функции isFish помогает при вызове функции неявно привести параметр creature к нужному типу, по сути сузив его:
function action(creature: Fish | Bird) {
if (isFish(creature)) creature.swim(); // Это Fish
else creature.fly(); // А это Bird
}
Но что, если тип объекта, в котором проверяется наличие свойства, неизвестен? Что будет, если мы попробуем проверить, существует ли свойство в объекте с заранее неизвестным типом? Рассмотрим следующий пример, более приближенный к жизни:
function getConfigVersion(config: unknown) {
if (config && typeof config === ‘object’) {
if (‘version’ in config && typeof config.version === ‘string’) {
return config.version;
}
}
return undefined;
}
В этом примере мы пытаемся получить свойство version из параметра, чей тип невозможно предсказать заранее. В первой проверке неявно приводим config к типу object, во второй убеждаемся, что свойство version типа string есть в объекте. Но почему-то получаем ошибки:
Property ‘version’ does not exist on type ‘object’.
Property ‘version’ does not exist on type ‘object’.
В чем дело? Оказывается, оператор in строго ограничен типом, который фактически определяет проверяемую переменную. Тип переменной config уже известен как object, соответственно, ни к чему другому приведение в данном случае невозможно: дальнейшая работа с переменной затруднительна.
TypeScript 4.9-beta исправляет это поведение. Вместо того, чтобы оставлять объект «как есть», добавляет к типу Record<"property-key-being-checked", unknown> . Переменная config после всех проверок будет иметь тип object & Record<"version", unknown>, что позволит функции выполниться без ошибок.
Больше информации по теме — в гитхабе Microsoft
Not a number
TL;DR Прямое сравнение с NaN теперь запрещено.
NaN — это специальное числовое значение, обозначающее что угодно, но не число. NaN — единственное значение в JavaScript, которое при сравнении с самим собой с помощью оператора строгого равенства (===) дает false. То же происходит при сравнении с любыми другими значениями. То есть ничто не может быть равно NaN — даже NaN!
Примеры типов операций, которые возвращают NaN:
-
Неудачное преобразование чисел. Например, parseInt(«not_a_number»).
-
Математическая операция, результат которой не является действительным числом. Например, Math.sqrt(-1).
-
Метод или выражение, операнд которого является NaN или приводится к нему. Например, 42 * NaN.
То есть наткнуться на NaN в своем коде вполне реально. Это приводит к тому, что разработчики могут случайно сравнить результат операции напрямую с NaN:
parseInt(someValue) !== NaN
Что, как следует из определения, приведёт к логической ошибке, которую можно сразу не заметить: выполнить такую проверку ничто не мешает, и разработчик всегда будет получать true.
Решение проблемы — запрет на прямое сравнение с NaN. В бета-версии TypeScript 4.9 сравнение возможно только через специальный метод Number.isNaN, который позволит избежать логических ошибок при сравнении.
Теперь разработчики видят ошибку:
TS2845: This condition will always return ‘true’.
Did you mean ‘!Number.isNaN(…)’?Отслеживание изменений
TL;DR Изменена стратегия по умолчанию для отслеживания изменений — механизм File System Events.
В более ранних версиях TypeScript для отслеживания изменений использовалась стратегия опроса — pooling: периодическая проверка состояния файла на наличие обновлений. В этом подходе есть плюсы и минусы. Например, такой способ отслеживания изменений считается более надежным и предсказуемым на разных платформах и файловых системах. Однако если кодовая база большая, то отслеживание изменений путём опроса может серьезно повысить нагрузку на ЦП и привести к перерасходу ресурсов.
В TypeScript 4.9 стратегией по умолчанию станет механизм событий файловой системы — File System Events. Он основывается на подписке на событие изменения файлов и выполнение кода только тогда, когда это событие произошло. Таким образом, отпадает необходимость периодических опросов. Для большинства разработчиков это нововведение должно обеспечить гораздо более комфортный опыт при работе в режиме —watch или при работе с редактором на основе TypeScript.
Настроить отслеживание изменений по-прежнему можно с помощью переменных среды и watchOptions.
Подробнее — в хендбуке TypeScript
Что дальше
Команда разработчиков продолжает разработку TypeScript 4.9 и в начале ноября планирует выпустить окончательный релиз. Ждём!
А пока что можно установить себе бета-версию и попробовать новые фичи:
npm install -D typescript@beta
Следить за планом итераций TypeScript 4.9.
Почитать про другие изменения бета-версии.

React tips for faster development at scale / Хабр | Веб-студия Nat.od.ua
React tips for faster development at scale / Хабр
Впервые я познакомился с React в 2015 году и вот уже использую его можно сказать повседневно 7 лет. Бесчисленное количество компонентов было написано за это время, React из подающей надежды модной технологии вырос в серьезную библиотеку и по сути стал стандартом для написания веб приложений в 2022 году.
Мы полюбили эту библиотеку за простое и лаконичное, но в тоже время очень мощное API, производительность, крутейшее коммюнити, наличия множество npm пакетов и просто за возможность решать прикладные задачи быстро и легко.
Скриншот официального сайта https://reactjs.org
Много споров в интернете, про то называть React библиотекой или фреймворков, но на официальном сайте написано библиотека, наверное им виднее.
В целом я согласен, поскольку React достаточно гибкий и в целом никак не диктует разработчикам как именно писать приложения, оставляя простор для воображения или для других разработчиков.
Решил собрать несколько советов, которые за эти годы доказали свою эффективность и масштабируемость уже не в одном проекте.
Примеры будут расположены не по важности, а скорее просто в рандомном порядке в котором я про них вспомнил, наверняка многие из них вы уже используете в своей кодовой базе, по скольку я не уверен что хотя бы один из этих паттернов я придумал сам, а не подсмотрел у других разработчиков, но так или иначе, это не отменяет их эффективности.
Design system driven development
Да этот совет не совсем про React, а скорее про организацию разработки и взаимодействия с дизайнерами. Если у вас есть возможность инвестировать время в e2e дизайн систему от Figma/Sketch макетов до React компонентов, это действительно помогает экономить время при решении бизнес задач с развитием проекта.
Единая цветовая палитра/шрифты, вертикальный ритм, компоненты и модули, с одинаковым неймингом позволят вам очень быстро переносить интерфейсы с макетов в код. Кстати ребята из Figma даже запалили плагин, который при корректной настройке сможет прямо в макете подсказывать какой компонент с какими props нужно использовать разработчику для реализации этого интерфейса
Ссылочка тут.
Чтобы подытожить, тема 10/10 чем раньше на стадии жизненного цикла проекта начнете тем легче и лучше будет.
KISS
Пытаться сохранять компоненты простыми это очень важно для их дальнейшей поддержки, масштабирования и переиспользования.
Безусловно есть случаи, когда сложность логики не позволяет сохранить API компонента простым и чистым, но нужно пытаться декомпозировать на переиспользуемые более простые слои и абстрагировать “сложный” код в одну из них.
Этот подход например очень важен при создании дизайн системы, нужно соблюсти грамотный баланс между гибкостью и строгостью API ваших компонентов, чтобы они могли скейлиться, но в то же время вы не теряли контроль.
Тут нету золотого стандарта, потому что строгость и гибкость в данном случае обратные понятия и вам нужно будет решить самостоятельно исходя из размера команды, зрелости проекта и прочих условий.
import React from ‘react’
export default function UILibInputSelect(props) {
const {
dataTestID,
className,
children,
onClick,
} = props;
return (
{children}
);
}
UILibInputSelect.useValue = useValue
const useValue = ({ initialItems }) => {
const = React.useState(initialItems);
const getCheckedItems = (items) => items.filter(({ checked }) => checked);
const onChange = React.useCallback(
(id: string) => setItems(items.map(item => ({…item,checked: id === item.id}))),
,
);
const checkedItems = React.useMemo(() => getCheckedItems(items), );
const onReset = React.useCallback(() => setItems(initialItems), );
return useMemo(
() => ({ items, onChange, onReset, checkedItems }),
,
);
};
UI Agnostic components
В IOS, Android и многих других нативных клиентах, платформа предоставляет разработчик достаточно высокоуровневые абстракции компонентов, которые уже решают за вас проблемы унификации низкоуровневых интерфейсов, accessibility, производительность и сложные UX приемы..
К сожалению в Web разработке у нас такого нет, некоторые html теги вполне себе являются этой абстракцией, но к сожалению они более низкоуровневые и их не много.
Если вы меняли команды/проекты/компании работая во фронтоне последние лет 5 вы замечали, что приходя в новую команду, часто вам приходится создавать те же самые компоненты, как и в прошлой, только в новой теме. Так вот чтобы решить эту. Проблему и сэкономить время, можно использовать UI Agnostic или Headless компоненты.
Идея этого подхода заключается как раз в том, чтобы иметь готовый набор решений, на которые можно добавить абстракцию темы и получить готовую дизайн систему со знакомым интерфейсом и уже реализованным низкоуровневым функционалом, который так долго и сложно каждый раз изобретать снова.
Альтернативой тут могут служить уже готовые библиотеки компонентов вроде MUI, Bootstrap, AntDesign и многих других, но не все продуктовые команды будут готовы пожертвовать гибкость. Headless компоненты дают больше свободы разработчикам,, но и ответственности тоже становится больше.
Примеры библиотек куда посмотреть: HeadlessUI, BaseWeb и другие
Binary doesn’t scale
Component props в React это по сути маленький уровень API компонента, с которым другие разработчики будут взаимодействовать при его переиспользовании, по сути это одна из самых важных и ответственных частей в написании компонент. Так вот кроме упомянутого выше KISS, которого нужно придерживаться здесь еще один полезный совет, старайтесь избегать булевых флагов в интерфейсах если логически интерфейс пусть даже и не прямо сейчас, но в будущем может иметь третье и более значение, используйте Enum, String Union.
import React from ‘react’
export default function UILibInputSelect(props) {
const {
variant,
dataTestID,
className,
children,
onClick,
} = props;
switch (variant) {
case UILibInputSelectVariant.small:
return (
{children}
);
default:
case UILibInputSelectVariant.default:
return (
{ children }
< /UILibInputSelect>
);
}
}
UILibInputSelect.useValue = useValue
UILibInputSelect.variant = UILibInputSelectVariant
React Component as Namespace
Этот совет плавно вытекает из предыдущего, чтобы не заставлять разработчика думать откуда импортировать значение props-ов, зная, что в js все — объект, можно положить сами значения внутрь компонента в статичные свойства под теми же именами что и props-ы и переиспользовать их вместе с компонентом.
Этот небольшой совет помогает ускорить разработку и сохранить консистентность кода в команде, со временем все разработчики привыкнут, что запрашиваемые статичные типы параметров уже предоставлены наборов в используемом компоненте, в купе со статической типизацией это позволит сократить время поиска корректных параметров.
import React from ‘react’
const App = () => {
return
}
CSS in JS
Если ваш проект вам позволяет, используйте css in js решения, они решают множество проблем классического css или css modules, а производительность их уже хороша. Самое популярное решение здесь это styled-components. У них непривычный синтаксис, но к этому привыкаешь и тебя перестает тоншить, а бенефиты остаются
Плюсы:
- Возможность задешево передавать динамическое значение в стили без оверхед.
- Типизация.
- Dead Code Elimination.
- Хорошо подходит для реализации дизайн систем.
Минусы:
- Ниже производительность.
- Синтаксис.
- Не подходит для анимаций.
Строгая статическая типизация
В 2022 году если вы не разрабатываете проект с очень коротким жизненным циклом, то использование языка со строгой статической типизацией уже must have.
Самым популярным выбором конечно же является Typescript. Быстрый, гибкий, хорошо интегрируемый с JS, React экосистемой и средами разработка, имеющий широкое признание в сообществе — отличный выбор.
Кроме того, что вы получите дополнительный слой безопасности для вашего приложения, вы еще и лишитесь постоянной мороки с поддержанием пачки Babel плагинов, получите более минималистичный конфиг и меньше мороки по настройке.
Также связка Typescript со средой программирования поможет ускорить разработку за счет умных подсказок для параметров функций, props-ов компонентов и прочего.
Автоформатирование кода и линтинг
К сожалению ни JavaScript ни TypeScript не имеют встроенного функционала по автоформатированию кода, но я настоятельно рекомендую озаботиться этими проблемами в начале проекта.
Это поможет вам не только поддерживать кодовую базу в едином стилистике, но и уменьшит число конфликтов внутри команды на этой почве. Также наличие единой стилистики написания кода ускоряет разработку в целом, человеческий мозг любит повторяющиеся паттерны, они усваиваются проще и быстрее.
Используйте Prettier и ES/TS-lint в связке, они уже стали можно сказать стандартами для разработки.

как обойти ограничения OpenStreetMaps / Хабр | Веб-студия Nat.od.ua
как обойти ограничения OpenStreetMaps / Хабр
OpenStreetMaps — это Open Source продукт, в котором 9 млн человек со всего Интернета создают свободную карту мира. Также это бесплатная альтернатива Google Картам при коммерческой разработке. Главная проблема такого продукта в том, что его сложно оптимизировать, а данные могут размечаться по-разному.
Сегодня я хочу поделиться с вами опытом нашего Go-разработчика Владимира, который знает, с какими трудностями можно столкнуться при использовании OSM в создании сложных продуктов с использованием геоданных и как их обойти.
Cтатья впервые была опубликована на Tproger.
Про инструмент
OpenStreetMap, или OSM, несмотря на название, нельзя назвать картой в привычном понимании этого слова. На самом деле это база данных, которая содержит сведения о точках земной поверхности, которая заполняется по принципу Wiki — каждый зарегистрированный пользователь может внести свои изменения. В ход идут данные GPS-трекеров, панорамы улиц или, например, спутниковые снимки. В результате от каждой точке поверхности собирается большой объем данных, на основе которых можно строить карты различного назначения.
Обратная сторона такой гибкости — «разношерстность» сведений, один и тот же параметр может быть записан в разных форматах. Кроме того, исходные данные почти всегда оказываются избыточными для каждой конкретной задачи и нуждаются в фильтрации и приведению к единому виду.
О задаче
Я принимаю участие в разработке системы мониторинга грузового и муниципального транспорта, которая отслеживает передвижения техники, подключенной к региональной навигационно-информационной системе (РНИС) по городу и в области, а также между регионами ЦФО.
Задача сервиса, о котором пойдет речь, — получить координаты от транспортных средств (автобусы, маршрутки, поливальные машины, грузовая и уборочная техника), определить дороги, по которым они движутся, и выяснить максимально разрешенную скорость. Если зафиксировано нарушение — сообщить об этом и записать информацию в лог, который анализируют операторы РНИС.
Если совсем просто, то наша задача состоит в определении скоростного режима на автомобильных дорогах и фиксации нарушений.
Из OpenStreetMap получаем данные о разрешенной скорости в каждой точке. Обработка осуществляется с помощью библиотеки S2 от Google, реализация на Go. Источником данных о самих машинах служат их GPS-датчики.
Проблема 1. Быстродействие
Overpass API — распространенный сервис доступа к OSM, который позволяет извлекать данные по пользовательскому запросу. Наша система работала с инстансом сервиса, развернутым в нашей сети.
По мере роста трафика производительности этого решения стало не хватать. Сервис превратился в бутылочное горлышко, время получения ответа от него росло. Внутренние сервисы системы обращались друг к дружке, а в итоге вся система терпеливо дожидалась ответа от Overpass. Фактически, запрос скорости для десятка точек под нагрузкой мог занимать до секунды.
Решение: разработали новый сервис, который мог бы заменить собой функционал Overpass API. В качестве источника остается OSM. Разрабатываемый сервис парсит данные и на их основе строит B-Tree индекс. В качестве ключа используем s2 CellId, сгенерированный для координат точки. API сервиса реализован с использованием gRPC.
Проще говоря, новый сервис выкачивает дампы базы данных OSM, не обращаясь к API, и строит поисковый B-Tree индекс.
Проблема 2. Импорт и индексирование данных
OpenStreetMap работает с данными в двух форматах — .osm и .pbf. В качестве формата для импорта мы использовали pbf, так как он более компактный, чем .osm.
Для представления данных на картах используется несколько типов элементов:
-
Точки (Node). Имеет координаты и id, опционально может иметь список тегов.
-
Пути (Way). Упорядоченная совокупность точек (от 2 до 2000), опционально также может иметь теги.
-
Теги (Tag). Основной способ описания географических данных, каждый тег представляет из себя пару ключ-значение.
-
Отношения (Relation). Используются для описания областей на карте, могут содержать теги.
Наибольший интерес для нас представляют элементы типа Way, так как они содержат данные о максимально разрешенной скорости. Имея координаты точек, из которых строятся пути, мы можем построить индекс и использовать его для определения участка дороги.
К сожалению, сразу проиндексировать путь не получится, так как он содержит в себе не координаты точек, а их ID. То есть сервису необходимо держать в памяти отображение ID точек и через них вычислять координаты. Учитывая объёмы — для центрального федерального округа дамп данных в формате .pbf имеет размер 680 Мб, процесс индексирования становится очень ресурсоемкой операцией.
Решение: подготовим данные перед импортом, используя утилиту для работы с данными OSM — osmium. После скачивания данных, запускаем команду:
osmium add-locations-to-ways —output=./prepared-data.osm.pbf ./data.osm.pbf
Когда команда выполнится, в файле ./prepared-data.osm.pbf получим дамп данных, в котором пути вместо ID точек содержат их координаты.
Проблема 3. Разметка данных
Индексы строятся по конкретному полю, а так как координаты точки состоят из двух чисел, то возникает вопрос, как построить индекс по двум полям.
Решение: для работы с s2 в golang есть библиотека geo, с её помощью будем генерировать cellId и использовать его в качестве ключа для поиска по индексу.
Кроме cellId индексируемый элемент должен будет содержать максимально допустимую скорость. Определять ее будем на этапе индексации. Сделать это можно двумя способами: по тегу «maxspeed», либо, если «maxspeed» не указан (что бывает довольно часто), по тегу «highway».
Ограничение скорости может быть указано как в виде числового значения (в км/ч, или реже для России, в милях в час), так и в формате констант, описанных в wiki OpenStreetMap.
Пример реализации:
// Максимальное разрешение
const StorageLevel = 18
coords := make([][]float64, 0, len(Way.Nodes))
// формируем слайс пар точек координат
for _, n := range Way.Nodes {
p := n.Point()
coords = append(coords, []float64{p.Lon(), p.Lat()})
}
// Формируем полигон из точек пути
polygon := geojson.NewLineStringGeometry(coords)
// Генерируем id для индексируемого пути
id := uuid.New()
// Полезные данные
md := Metadata{
MDMaxSpeedKey: wms.MaxSpeed,
}
// Создаём из точек пути регион с нужным разрешением, таким образом
// добиваемся интерполяции с заданным разрешением
cover := s2.RegionCoverer{
MinLevel: 0,
MaxLevel: StorageLevel
MaxCells: math.MaxInt64,
}
cells := cover.InteriorCovering(polygon)
// Добавляем полученные CellId в индекс
for _, cellID := range cells {
index.AddPoint(&IndexPoint{
CellID: cellID,
Geometry: &IndexedGeometry{
UUID: id,
GeometryType: polygon.Type,
Geometry: polygon,
Metadata: md,
}
})
}
***
В итоге мы получили сервис, в котором каждый запрос обрабатывается меньше одной миллисекунды. На его создание ушло примерно три недели: от старта исследования до разработки. Сейчас мы готовим prod-решение, оформление его в виде gRPC-сервиса и интегрируем в РНИС.
Если остались вопросы — предлагаю обсудить в комментариях.

